Python機械学習プログラミング 達人データサイエンティストによる理論と実践
![[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)](https://m.media-amazon.com/images/I/51j2a-lVLyL._SL500_.jpg "[第3版]Python機械学習プログラミング 達人データサイエンティストによる理論と実践 (impress top gear)")
第5章
次元削減でデータを圧縮します.
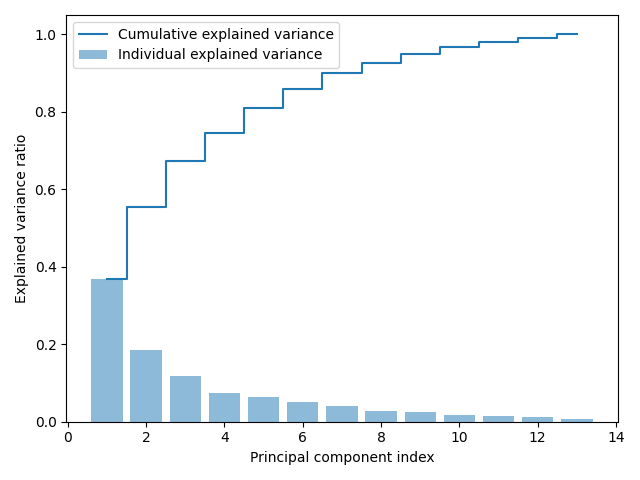
分散説明率
情報利得が大きい固有ベクトルを採用するために分散説明率を利用します.
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import numpy as np import matplotlib.pyplot as plt df_wine = pd.read_csv('D:\\Book\\python-machine-learning-book-3rd-edition-master\\ch05\\wine.data', header=None) X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=0) sc = StandardScaler() X_train_std = sc.fit_transform(X_train) X_test_std = sc.fit_transform(X_test) cov_mat = np.cov(X_train_std.T) eigen_vals, eigen_vecs = np.linalg.eig(cov_mat) tot = sum(eigen_vals) var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)] cum_var_exp = np.cumsum(var_exp) plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='Individual explained variance') plt.step(range(1, 14), cum_var_exp, where='mid', label='Cumulative explained variance') plt.ylabel('Explained variance ratio') plt.xlabel('Principal component index') plt.legend(loc='best') plt.tight_layout() plt.show()